[FR] Passer de EMR vers Kubernetes pour les workloads Spark
Last updated: Jul 1, 2021
AWS EMR est un service AWS largement utilisé principalement pour le traitement des données massives avec Apache Spark dans un Cluster Hadoop dédié. Au-delà de sa fonction principale, EMR embarque un bon nombre d'outils open-source, certains pour le monitoring (Ganglia), et d'autres pour le requêtage des données (Hive). Plus d'informations peuvent être trouvées par ici. Dépendamment du contexte, EMR peut être utilisé soit en tant qu'instance d'un cluster éphémère (par exemple en lançant un Cluster tous les 6 heures pour exécuter des jobs Spark), soit en tant que cluster permanent. C'est le cas notamment lorsque celui-ci est utilisé par plusieurs équipes, fait tourner des jobs de streaming ou lorsque l'attente de son instanciation est plus coûteuse que de le laisser tourner de manière permanente. Cet article n'est pas nécessairement un texte pour comparer EMR à Kubernetes vu que les deux ne répondent pas aux mêmes besoins. Kubernetes s'impose de plus en plus aujourd'hui pour des raisons diverses et variées, et Spark supporte Kubernetes comme Scheduler et Resources Manager nativement, donc ça aurait été dommage de ne pas s'y pencher.
La valeur de ce service n'est plus à prouver vu son utilisation massive et sa fiabilité. Pour autant, certains de ses avantages incluent (et ne sont pas limitées à) :
- Intégration avec l'écosystème AWS.
- Écosystème Hadoop quasi-complet dans un seul et même service.
- Auto-Scaling du cluster : EMR se base sur des instances EC2, et fait la différence entre deux types de slave nodes : les Core Nodes et les Task Nodes. Ces derniers peuvent être upscalé ou downscalé sans que les données stockées dans le tampon HDFS du cluster ne soient perdues, et ça, c'est cool. A noter ici que le système de stockage distribué (HDFS) inclut dans EMR n'est pas à utiliser en tant que système de stockage principal, même dans le scénario où le cluster est permanent.
- Haute disponibilité : EMR détecte les nodes unhealthy et les remplace lorsque c'est nécessaire (en réalité, le name node est assez grand pour détecter les data nodes en difficulté lui-même, mais EMR rajoute sa petite touche en faisant en sorte de les remplacer à la volée).
- Accès aux données stockées dans S3 : Qui a parlé d'avoir le stockage de son datalake directement avec S3 ? Idée de génie !
Bon alors, puisque EMR est aussi cool que ça, de quoi on parle ?
- EMR est un service très complet, donc lourd, et donc chiant à migrer (si le CTO de ta boite ne t'a pas encore parlé de sa superbe idée de faire du multi-cloud ou de migrer vers GCP, ce n'est qu'une question de temps, tu verras). Et c'est là que tu te trouveras devant un désavantage assez conséquent d'EMR : il est difficilement portable. Bien évidemment, si la seule utilisation que tu en fait c'est celle de faire tourner des jobs Spark (ce qui serait dommage), alors pas de soucis ; par contre si tu utilises ses features plus avancées comme l'auto-scaling, ou si ton équipe utilise plutôt Hive qu'Athena pour requêter les données (ce qui serait dommage aussi, vraiment), là ça devient plus compliqué.
- EMR est un service très complet, et donc cher, et on sait tous que l'ami Bezos ne fait pas de charité… Enfin si, parfois. Bref, lorsqu'on plonge le nez dans le pricing, on voit que lorsqu'on utilise des instances EC2 m5 classiques (On Demand), le prix pour EMR est 25% supérieur ; ce prix peut aller jusqu'à 33% pour des instances spot.
- De plus en plus d'entreprises aujourd'hui se basent sur Kubernetes pour beaucoup de leurs use cases ; souvent, ceux-ci sont oversizés et sous utilisés… Tu commences à voir l'idée ?
Du coup, tu as un cluster Kubernetes sous la main qu'on te propose d'utiliser, EMR te coûte trop cher (tu le sais et tu t'en fous, mais le CFO de ta boite râle car en plus il n'y comprend rien) et en plus, tu ne l'utilises que pour lancer tes jobs Spark 3 fois par jour pour exposer des données à tes amis Data Analysts ? Bouge pas, t'es à la bonne adresse.
Par contre, si tu utilises toute la panoplie des outils proposés par EMR et que tu ne peux pas t'en passer, que t'as réussi à convaincre ton CFO que c'était normal que ça soit cher et que ton CTO ne regarde pas BFM ou n'est pas intéressé par le Multi-Cloud car lui, au moins, est conscient qu'il n'en sait rien, alors passe ton chemin, ou regarde par ici, AWS a sorti un truc qui devrait pouvoir t'intéresser.
Bref, comment ça marche ?
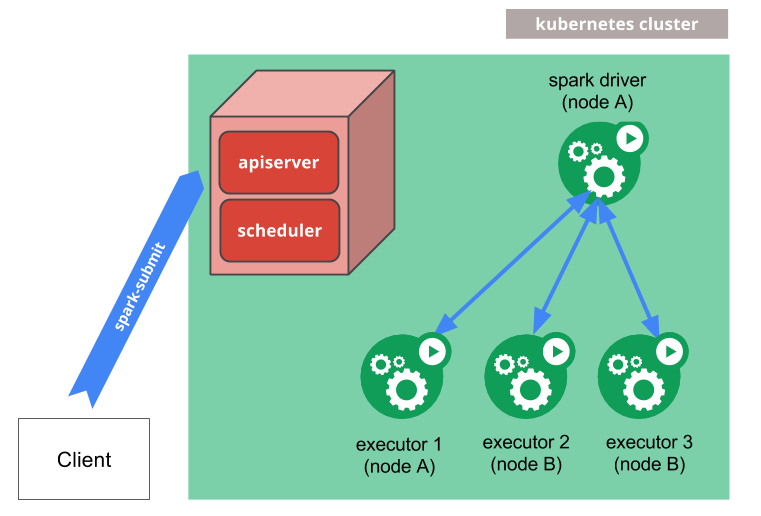 Lorsqu'on décide de faire tourner nos jobs dans Kubernetes, on laisse tomber YARN (Yet Another Resource Negociator), qui avait, rappelons le, brillamment réussi à détrôner Map Reduce.
Lorsqu'on décide de faire tourner nos jobs dans Kubernetes, on laisse tomber YARN (Yet Another Resource Negociator), qui avait, rappelons le, brillamment réussi à détrôner Map Reduce.
Comme le montre le schéma, notre commande spark-submit s'adressera à l'api-server (comme tout dans Kubernetes d'ailleurs), qui lui s'occupera de :
- Demander la création d'un Spark Driver sous forme d'un pod.
- Ce pod lancera la création (suivant la configuration du job) d'autres pods qui joueront le rôle d'exécuteurs.
- Une fois le job terminé, tous les exécuteurs sont détruits, sauf le Pod contenant le Spark Driver, qui lui persistera ses logs sur disque et se mettra en état “completed” et sera détruit plus tard (manuellement si t'es impatient, car de toutes façons il ne consomme rien).
Et concrètement, on fait comment ?
Si tu es familier avec Docker et Kubernetes, cela devrait aller rapidement pour toi, sinon… Qu'attends-tu pour aller acheter Kubernetes In Action ???
- Builder l'image Docker : Celle-ci peut être située dans ton registry d'images préféré (ECR, Gitlab…). Ou alors, tu peux utiliser l'outil fourni par Spark si tu n'as pas envie d'utiliser de registry :
./bin/docker-image-tool.sh -r <repo> -t my-tag build
./bin/docker-image-tool.sh -r <repo> -t my-tag push
- Une fois ton image prête à l'emploi, l'étape d'après est naturellement ton spark-submit. Cela ne diffère pas des spark-submit auxquels on a l'habitude hors Kubernetes, à la différence près de l'adresse du Master (exemple pour l'exécution en mode cluster) :
./bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name nom-de-ton-job \
--class org.apache.spark.examples.TaMainClass \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/examples.jar
- Une fois ton job en route, tu peux le suivre en utilisant la SparkUI, avec la commande suivante :
kubectl port-forward <driver-pod-name> 4040:4040
L'avantage d'utiliser Spark, parmi d'autres évidemment, est qu'il est possible d'utiliser tous les objets natifs Kubernetes desquels nous étions privés avant : RBAC, Secrets, etc…
Les Volumes
Il est possible de monter les volumes Kubernetes suivants (à la fois au niveau du driver et des exécuteurs) :
- hostPath
- emptyDir
- nfs
- PVC
Ce qui est intéressant dans les volumes locaux c'est que les shuffles, les étapes intermédiaires nécessitant une persistence disque (les checkpoints par exemple) se font sans trop solliciter le réseau, ce qui peut potentiellement nettement améliorer la performance de nos jobs (après, si tu t'amuses à bidouiller tes NFS pour stocker ta data dans S3, c'est ton problème).
Déjà, énormémemnt de flexibilité… et d'argent. Faire tourner des jobs Spark sur Kubernetes te coûtera nécessairement moins cher. Cela dit, tous tes devs ne sont pas nécessairement familiers avec la techno, et du coup, ça peut potentiellement te faire perdre beaucoup (en terme de temps surtout), au moins sur le court / moyen terme.
La migration dépend donc de ton équipe, de sa maturité et de l'envie d'apprendre une nouvelle techno, du temps que tu as à allouer à cette migration (car soyons honnêtes, si tes jobs Spark n'ont pas de tests unitaires et sont sous-optimisés, je te conseillerais plutôt de commencer par là).
Dans tous les cas j'espère que cet article te permettra d'y voir un peu plus clair et que tu pourras au moins essayer de déployer tes premiers jobs Spark sur Kubernetes histoire au moins de voir “à quoi ça ressemble”.